The legislation either already in place or coming soon[1][2][3] in support of “right to explainability” has made it clear that being able to defend outcomes due to automated decisioning and machine learning is increasingly important.
Is this approval model fair?

Hint: if you said no – read on. In this blog post, you’ll learn how and why InRule Machine Learning can save your data science teams time and money when developing and evaluating models.
In research conducted with Forrester Consulting, we asked firms how critical it is to defend their algorithms. Sixty-four percent said it’s critical or important, while 84% said it’s somewhat to very challenging.
We understand.
That’s why we introduced bias detection features for our machine learning platform, InRule Machine Learning, designed to identify harmful bias using fairness through awareness.
What is harmful bias?
Harmful algorithmic bias occurs when a computer system performs differently for people based on characteristics that should not be relevant to the process.
Doesn’t everyone have bias detection?
It seems like every machine learning platform claims to have some type of bias detection. But can they truly deliver fairness through awareness? Let’s look at some techniques.
Measuring population shift over time
This is a relatively standard practice and something we, too, enable teams to do with InRule Machine Learning. This technique enables data science teams to measure the potential for sample selection bias.
What is sample selection bias?
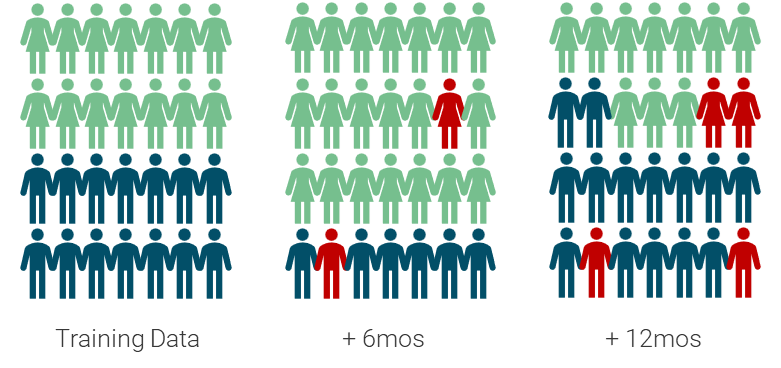
Imagine you have a retail consumer behavior model which has been trained on holiday season data. By the time summer rolls around, if you’re still using that model to predict consumer behavior, it wouldn’t be a good model to predict consumer behavior now.
Measuring population shift over time is a good practice in model operations. But, while this is a way to detect a type of bias, this by itself isn’t an indicator of fairness.
Removing protected characteristics from training data before training
The next question we often get is, “What if I just exclude the protected characteristic from my data? Won’t that keep my model free from bias? I mean, I am not even using the protected characteristic to build the model.”
The short answer? No.
The challenge is that modern automated decisions and machine learning models are built with increasingly correlated elements. Removing the data can actually increase risk by reducing transparency and visibility.
While there is the concept called “fairness through blindness,” simply removing a characteristic that is highly correlated to things that remain in your data severely hampers your ability to see just how harmfully biased your model may unintentionally be.
For example, let’s say we want to remove gender as a characteristic from our data. However, we leave the data for marital status and dependents in. According to the Pew Research Center, 81% of single parents in the US are female – so the two columns we’ve left in are highly correlated with gender, and we’ve removed the one that could help us evaluate whether or not our model is, in fact, harmfully biased whether directly or indirectly.
With InRule Machine Learning, we allow teams to keep information like that in, but as metadata. This enables it to be present and statistically useful for the purpose of evaluating whether a model is fair, without being included in the actual creation of the model itself.
This means your enterprise can measure and mitigate potential risks with true visibility and transparency.
Measuring average accuracy
Surely there are platforms out there that enable data science teams to easily determine fairness, right? Well, yes, and no. Let’s look at our example from the beginning of this post:

Let’s say that we are looking at a machine learning model built from the outcome of hundreds of thousands of loan approval decisions. A traditional ML model’s “fairness metric” would say that this model isn’t fair because the average accuracy (shown on the far right of the above image) is significantly worse for women of color than it is for Caucasian men.
What does that mean to you? Potentially wasted time and money.
How can organizations discover harmful bias in their policies and practices?
With InRule Machine Learning’s clustering capabilities, we can look within and between clusters to determine that, when your approval processes (in the form of things like automated decisions, machine learning models, digital processes) saw applicants with the same relevant factors for a given decision, they were treated fairly.

For example, when examining Cluster A, we see that all the factors that are appropriate for an approval decision are exactly the same within this cluster. And, when we examine within the cluster based on gender and/or race, we can see that the two groups we’re interested in within this cluster were treated the same (the model had an accuracy of 0.95 across the board when comparing women of color versus Caucasian males within Cluster A).
We see the same is true in Cluster B.

Lack of this level of visibility can introduce bottlenecks in your model lifecycle as teams are forced to manually evaluate the ethics and fairness of models. This slows down your ability to be responsive to the market and new regulations that may impact what happens should harmful bias be detected.
Instead, InRule Machine Learning gives data science teams a suite of automatic tools to do this. As a result, enterprises are able to:
- Reduce risk
- Deliver greater transparency
- Quantify and mitigate potential hazards when complying with federal, state and local regulations or corporate policies
- Take action (for example, in automated decisions) based on analytic data, available via API
This has applicability far beyond just examining loan approvals, of course. InRule Machine Learning enables organizations to ensure fairness through awareness in a variety of applications, including:
- Benefits determination and administration
- Claims adjudication
- Corrections sentencing
- Patient population segmentation & targeted care
- Enrollment eligibility
- Performance evaluations
Ready to explore how InRule Machine Learning can help your enterprise measure, mitigate or root out harmful algorithmic bias? Curious what else it can do? Start a free trial and explore everything InRule Machine Learning has to offer.
[1] New York City Law Seeks to Curb Artificial Intelligence Bias in Hiring | Seyfarth Shaw LLP
[2] Europe Proposes Strict Rules for Artificial Intelligence – The New York Times (nytimes.com)
[3] Text – H.R.6580 – 117th Congress (2021-2022): Algorithmic Accountability Act of 2022 | Congress.gov | Library of Congress