
Many customers are actively exploring machine learning (ML) and are asking for some simple recipes that can get them going quickly before they make a deeper plunge. That said, here are some of the high-level areas for your planning that will make a difference.
- Spend time with the business understanding what it is you want to predict. If you are analyzing a business process, what would you do differently if you knew something was likely to happen? A model on its own is not useful unless it can influence business outcomes. For example, some risk in a loan origination process could be managed more effectively if you could predict the price of a property for a mortgage. An originator could take action if the predicted price fell out of bounds when compared to the loan amount and the appraised value. In short, look for predictions that can be compared to existing values or useful to manage within a range variance with rules. This will be much more actionable for a business process.
- Unless your own data covers a large % of your problem domain, you need to look externally for data. Be prepared to augment your data from multiple sources to better understand the relationships. If your problem can be segmented down to a smaller set, that’s even better.
- Who on the team is in the best position to work with data? Rule authors work with data all the time (not just the transactional data). Which of them has experience based on data science such as Psychology or Sociology (these are not always obvious academic skills)? The basic foundation they have might be enough for data cleansing and experimentation with AutoML. If an outside consultant is needed, establish their track record of getting machine learning models prepared for production use. Rely on your consultant if you have trouble selecting an ML approach to your business problem (i.e. does this align with a regression or some other strategy?).
- Simulate the model with decisions together to fully understand business impact and KPIs. This will require a reasonable amount of real data to run the simulation and takes some extra time to put it all together.
- Whatever ML capability is used, the models must be deployed and made available as an API or service to be operational. This includes use within a decision management platform.
- Version your decision and machine learning models together (even if it is only by reference of a URL) to keep your lifecycle traceable for reuse in the form of future experiments.
- Combine your rule authors with data science team members when working on operational solutions. If for some reason a segment of data cannot be predicted by a model, then produce a decision by hand for coverage until the training data can be improved. Otherwise, keep the focus on the goals using both ML and Decisions as requirements dictate.
Once you have a reasonably good model, the critical step is operationalizing the model by exposing it as a service or API. Decisions are an excellent way to consume models because of their ability to interact with data pre-scoring and post-execution for processing. Models that are trained based on segments, can be routed between models (review wording here). Similarly, post execution, decisions can route to additional rule sets or additional ML models. At the end of the day, we believe ML models are more likely to be surrounded by decisions than compiled code because of their decision making capability.
There are two patterns for executing ML models in a decision. First, if your model is serializable and executable as .NET, then you can integrate the model into InRule as an “Assembly Endpoint.” This assembly is now a dependency and must travel with the rule application for deployment and testing. A more portable approach is to integrate the model as a “REST Endpoint.” This has several advantages but the most notable is that anyone can execute the decision and test it so long as the service for the ML model is available.
To demonstrate the integration, I downloaded a lending data set from Kaggle and prepared a pipeline using Microsoft Azure Machine Learning. After some time with the data set, I narrowed the features to the most salient Entity fields from my Decision with the highest predictive coverage. Not only do I have an improved model, but I also have fewer Entity fields to map in the integration. Below is my resulting pipeline used to generate my scoring service:
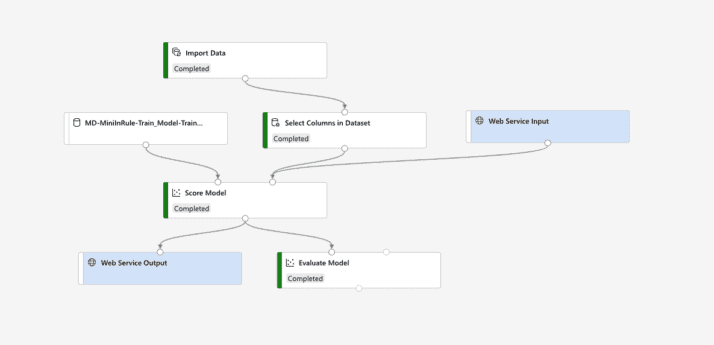
In my rule application, I isolated the ML prediction to just a few areas:
- The entity that will describe the scoring features

- The explicit ruleset that executes the REST call to Azure parses the result and sets the sale price

- Simple vocabulary to make my rule set more readable

- The REST endpoint and operation that map the POST back into the rule application.
In short, the integration of a machine learning model into InRule doesn’t vary from a typical REST service; however, this integration capability offers significant value add to projects that tackle business problems that require non-declarative, prediction-based logic. In a future post, we will explore how decision management makes ML more operational and aligned with business value.