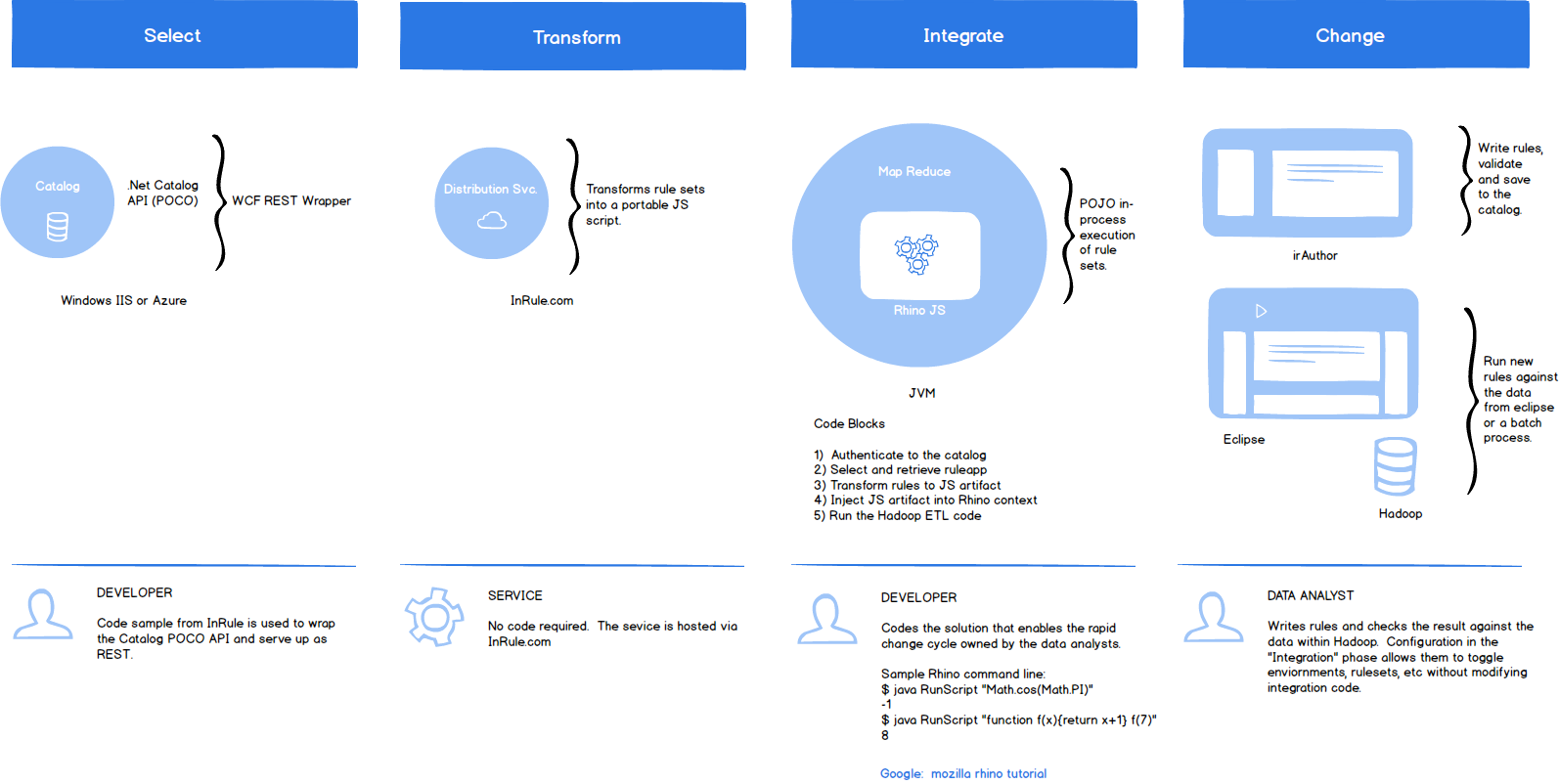
Recently I explored some of the decision management touch points with Hadoop. The most obvious was the classic ETL scenario where folks (analysts and data scientists) explore batch scenarios across large datasets—really big ones. While there are so many ways for our tooling to integrate, I became curious about JavaScript specifically. It’s generally fast and because it operates without the traditional “cold start” problem it scales really well in an instant. I imagined dropping our JavaScript decision inside a MapReduce artifact wrapped with something like Rhino. With just a few extra steps, Hadoop processes may operate with the benefits of a business decision and no service calls are required. In fact, with a little extra, it’s easy to imagine putting the parts and pieces together for a full Hadoop lifecycle:
- Selecting the decision you need from the catalog.
- Transforming the decision into a JavaScript artifact.
- Integrating your JavaScript decision and running it (with full automation).
- Making rapid changes to the decision and doing it all over again.
Just imagine the Data Analyst happily working with big data and decisions without friction.